How I Built an AI-Powered Website Template Search Engine
A couple of years ago, I started experimenting with AI for my own hobby projects. One concept that completely fascinated me was something called RAG—Retrieval Augmented Generation.
At its core, RAG is about combining the power of large language models (like GPT) with your own custom knowledge base or data. Here's how it typically works:
Your data is processed and stored in a vector database, enabling semantic search.
When a user asks a question, the system retrieves the most relevant information from your data.
The AI generates an informed response by combining this retrieved data with its general knowledge.
This concept got me thinking: what if I could build a tool where users could "chat" with data from a specific niche, like my own Squarespace template library? That led me to explore ways to build AI-powered search engines using RAG principles.
Fast forward to January 2023, when I realized GPT-4 could process images. That was the breakthrough I needed to start working on my Squarespace Template Search Engine. The goal? To help people find the perfect Squarespace template by simply describing what they’re looking for in plain language.
In this guide, I’ll walk you through how I built this system. By using AI (GPT-4o), vector databases (Qdrant), and a simple web interface (Gradio), I created a tool that lets users discover templates based on their needs, even if they don’t know the exact keywords.
Understanding the Big Picture
Let’s start with the big picture. The goal here is to build a system that allows users to find website templates by describing what they’re looking for in plain language. To do this, we’ll combine several tools and techniques to create an AI-powered search engine.
Even if you’re not a Python expert, don’t worry - I’ll break things down step by step. The key prerequisite is familiarity with basic coding concepts and some understanding of how AI models and APIs work.
You can use this to guide your own conversation with AI for whatever you want to build.
Collecting the Data
First I made a simple web scraper to collect template details (like name, designer, and image) from my own directory of website templates.Generating Detailed Descriptions
Using GPT-4 or Claude (via API), we’ll generate detailed, structured descriptions of each template. These descriptions make the templates easier to search.A Vector Database
We’ll store all the template data in a vector database, making it searchable using semantic search. This allows users to find templates even if they don’t use exact keywords.A Search Interface
Finally, we’ll build a user-friendly interface that lets users search for templates using natural language (like "modern design for a coffee shop"). This interface will pull relevant results from the database.
You can see how it works here: https://www.sqspthemes.com/template-matchmaker
Part 1: Data Collection
The first thing I needed to do was gather some basic information about all the Squarespace templates I wanted in the search engine. For this, I wrote a simple Python script to scrape data from my own directory of templates.
Here’s what I wanted to collect for each template:
Template Name
Designer
Link to the Template
Image URL
This process, called web scraping, is like sending a bot to a webpage to grab the data you need. Then, it organizes that data into a file so it’s easy to work with later.
How It Works
The script I wrote does four main things:
Fetches the webpage: It goes to the directory where all the templates are listed.
Parses the content: It figures out where each piece of information is on the page (like the template name, designer, etc.).
Extracts the data: It pulls out the details for each template.
Saves everything to a file: It creates a CSV file (like a spreadsheet) with all the collected info.
Here’s the code I used to scrape the data:
import csv
import requests
from bs4 import BeautifulSoup
# URL of the templates page
base_url = "https://www.sqspthemes.com/templates-d"
output_file = "templates.csv"
# Open a CSV file to save the data
with open(output_file, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["Image_url", "Link", "Template_name", "Designer"]) # Add headers
# Fetch and parse the webpage
response = requests.get(base_url)
soup = BeautifulSoup(response.content, "html.parser")
# Find and extract info for each template
for article in soup.find_all("article", class_="blog-basic-grid--container"):
image_url = article.find("img")["data-src"] # Grab the image URL
link = article.find("a", class_="passthrough-link")["href"] # Grab the template link
name_and_designer = article.find("h1").text.strip().split(" by ") # Split name and designer
# Write the data to the CSV file
writer.writerow([image_url, link, name_and_designer[0], name_and_designer[1]])
print("Done! The data has been saved to templates.csv.")
What’s Happening in the Code
Step 1: Set up the CSV file
Before collecting any data, the script opens a file calledtemplates.csvand adds headers like "Image URL," "Link," "Template Name," and "Designer."Step 2: Fetch the webpage
Using therequestslibrary, it downloads the HTML content of the template directory.Step 3: Parse and extract the data
With the help ofBeautifulSoup, it looks for specific parts of the webpage, like the image tags (<img>) for image URLs or the headline tags (<h1>) for template names.Step 4: Save the data
Once it pulls the details for each template, it writes them into the CSV file row by row.
the Output
After running the script, you’ll get a CSV file (templates.csv) containing rows like this:
Template Table
| Image_url | Link | Template_name | Designer |
|---|---|---|---|
| https://example.com/img1.jpg | https://example.com/template1 | Clean Design | John Doe |
| https://example.com/img2.jpg | https://example.com/template2 | Bold & Modern | Jane Smith |
How to Run This Script
Here’s how you can try this out:
Install Python: If you don’t already have Python on your computer, download it for free at python.org.
Install the required tools: Open a terminal (or command prompt) and type:
pip install requests beautifulsoup4Save the code: Copy the script above into a file called
scrape_templates.py.Run the script: In your terminal, navigate to the folder where you saved the file and type:
python scrape_templates.pyThis will generate the
templates.csvfile in the same directory.Check the results: The script will generate a file named
templates.csvin the same folder, containing all the data it scraped.
And that’s it! Now we have all the basic info we need to start building the rest of the system.
Part 2: AI Description Generation
Now that we’ve collected the basic details for each template, the next step is to give those templates some depth. This is where AI comes in. Using GPT-4 Vision, we can analyze each template's image and generate a detailed, structured description. These descriptions help users find templates more easily, even if their searches are vague or don’t use exact terms.
What We’re Doing
Here’s the game plan:
Send each template’s image to GPT-4 Vision.
Ask GPT to analyze the template and give us details like:
Template Type: What’s it for? (e.g., portfolio, e-commerce, blog)
Target Audience: Who’s this best suited for? (e.g., photographers, small businesses)
Design Features: Things like layout, colors, and fonts.
Unique Elements: Anything that stands out (e.g., animations, interactive sections).
Use these descriptions to make the templates searchable in smarter ways.
The Code
Let’s start with the function that sends the image to GPT-4 Vision and gets back a detailed description:
def generate_detailed_description(image_url):
"""Creates a detailed description of a website template using GPT-4 Vision."""
prompt = """
Please analyze the following Squarespace website template and provide a detailed, structured description optimized for semantic search using this JSON format:
{
"template_type": "Briefly describe the type or purpose of this template",
"target_audience": "Who would find this template useful?",
"design_elements": {
"layout": "How is the template structured?",
"color_palette": {
"primary": "Main color",
"secondary": "Secondary color",
"accent": "Accent color"
},
"typography": {
"heading_font": "Font used for headings",
"body_font": "Font used for text"
},
"visual_elements": ["List", "of", "notable", "visual", "features"]
},
"sections": ["Key", "sections", "of", "the", "template"],
"unique_features": ["What", "makes", "this", "template", "stand", "out?"],
"content_elements": ["What", "types", "of", "content", "are", "included?"],
"navigation": "Describe the navigation structure",
"keywords": ["List", "of", "useful", "keywords"]
}
"""
try:
# Use GPT-4 Vision API to generate the description
response = client.chat.completions.create(
model="gpt-4o", # Adjust to the correct GPT-4 model name
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": image_url}},
],
}
],
max_tokens=3000,
)
return response.choices[0].message.content # Return the AI-generated description
except Exception as e:
print(f"Error generating description for {image_url}: {e}")
return "{}" # Return an empty JSON string if there’s an error
Breaking It Down
The Prompt: This is what tells GPT-4 exactly what to do. It asks for:
A JSON-format description with structured details like template type, audience, and design features.
Enough detail to understand the template without seeing the image.
Sending the Request: The
client.chat.completions.create()function sends the prompt and image URL to GPT-4 Vision and retrieves the result.Handling Errors: If something goes wrong (e.g., bad image URL or API issue), the function returns an empty description so the program doesn’t crash.
Extracting the Good Stuff
Once GPT-4 gives us a description, it’s in JSON format. We need to pull out specific details to make them usable. Here’s how we do that:
def extract_metadata(description):
"""Extracts structured metadata from GPT-4's JSON description."""
if not description or description == "{}":
return [""] * 14 # Return empty fields if no valid description
try:
data = json.loads(description) # Parse the JSON
# Extract specific details with default values for missing data
return [
data.get("template_type", ""),
data.get("target_audience", ""),
data.get("design_elements", {}).get("layout", ""),
data.get("design_elements", {}).get("color_palette", {}).get("primary", ""),
data.get("design_elements", {}).get("color_palette", {}).get("secondary", ""),
data.get("design_elements", {}).get("color_palette", {}).get("accent", ""),
data.get("design_elements", {}).get("typography", {}).get("heading_font", ""),
data.get("design_elements", {}).get("typography", {}).get("body_font", ""),
", ".join(data.get("design_elements", {}).get("visual_elements", [])),
", ".join(data.get("sections", [])),
", ".join(data.get("unique_features", [])),
", ".join(data.get("content_elements", [])),
data.get("navigation", ""),
", ".join(data.get("keywords", [])),
]
except json.JSONDecodeError as e:
print(f"Error decoding JSON: {e}")
return [""] * 14 # Return empty fields if JSON is invalid
This function ensures we pull the right information, even if some fields are missing in the AI response.
Adding the Descriptions to Our Data
Here’s how we put it all together:
For each template, send the image URL to GPT-4 Vision.
Get the JSON description and extract the metadata.
Add this information to the existing template data.
# Apply the description generation to each row in the dataset
df['AI_Generated_Description'] = df['Image_url'].apply(generate_detailed_description)
# Extract metadata from descriptions and add it to new columns
df[[
'Template_Type', 'Target_Audience', 'Layout', 'Primary_Color', 'Secondary_Color', 'Accent_Color',
'Heading_Font', 'Body_Font', 'Visual_Elements', 'Sections', 'Unique_Features', 'Content_Elements',
'Navigation', 'Keywords'
]] = pd.DataFrame(
df['AI_Generated_Description'].apply(lambda x: extract_metadata(x)).tolist(),
index=df.index
)
# Save the updated data to a new CSV file
df.to_csv("template-cat.csv", index=False)
Why This Step Is Important
Smarter Search: With detailed descriptions, users can search for templates using natural language (e.g., "minimal layout with warm colors").
Better Experience: Users don’t have to click through every template to figure out if it’s a good fit.
Efficiency: Automating the description process means we can scale this system to hundreds of templates without manual effort.
With this step done, we’ve added another layer of intelligence to our system. Now the templates are rich with searchable data, making it easier for users to find exactly what they need.
Part 3: Setting Up the Vector Database
Now that we have detailed descriptions of our templates, we need to store them somewhere that makes them searchable by meaning. Enter Qdrant, a vector database designed for semantic search. Instead of matching exact words, it compares the meaning of text, which makes searches smarter and more flexible.
What’s a Vector Database, and Why Do We Need It?
A vector database stores embeddings—mathematical representations of text that capture meaning. This allows us to find templates based on what users mean, not just what they say. For example, if a user types "modern cafe design," Qdrant will find templates that fit this vibe, even if the exact phrase isn’t in the descriptions.
Step 1: Setting Up the Collection
The first step is to create a collection in Qdrant, which is like a folder where all the template data lives. Here’s the code from your project that sets up the collection:
import pandas as pd
import uuid
from tqdm import tqdm # For a progress bar
# Read the template data
df = pd.read_csv('Template-Catalog.csv')
# Define metadata columns to include
metadata_columns = [
'Template_Type', 'Target_Audience', 'Layout', 'Primary_Color', 'Secondary_Color',
'Accent_Color', 'Heading_Font', 'Body_Font', 'Visual_Elements', 'Sections',
'Unique_Features', 'Content_Elements', 'Navigation', 'Keywords'
]
# Function to generate embeddings
def get_embedding(text):
response = client.embeddings.create(input=[text], model="text-embedding-ada-002")
return response.data[0].embedding
# Process each template and add it to the database
points = []
BATCH_SIZE = 50
with tqdm(total=len(df), desc="Processing Templates") as pbar:
for _, row in df.iterrows():
# Combine metadata into a single text block
metadata = {col: str(row[col]) if pd.notnull(row[col]) else "" for col in metadata_columns}
text_to_embed = " ".join(metadata.values())
# Generate the embedding
vector = get_embedding(text_to_embed)
# Create the payload with metadata
payload = {
'image_url': row['Image_url'],
'link': row['Link'],
'template_name': row['Template_name'],
'designer': row['Designer'],
'metadata': metadata
}
# Add the data as a "point" in Qdrant
point = PointStruct(
id=str(uuid.uuid4()), # Unique ID
vector=vector,
payload=payload
)
points.append(point)
# Insert points into Qdrant in batches
if len(points) >= BATCH_SIZE:
qdrant_client.upsert(
collection_name=collection_name,
points=points
)
points = [] # Clear the batch for the next set
pbar.update(1)
# Final batch insertion
if points:
qdrant_client.upsert(collection_name=collection_name, points=points)
print("Template ingestion complete!")
Breaking It Down
Read the Data: Load the
Template-Catalog.csvfile, which contains the data for all templates.Generate Embeddings: For each template, combine its metadata (like layout and keywords) into a single text block and send it to OpenAI’s embedding model.
Create a Payload: Alongside the vector, we store extra details (e.g., image URL, link, and metadata) to make search results richer.
Batch Insertion: To avoid overloading the database, we insert templates in batches of 50.
What’s in the Database?
Once this process is done, the collection will contain:
Vectors: Representing the meaning of each template’s metadata.
Payloads: Metadata like:
Template Name
Designer
Layout
Colors
Keywords
This setup ensures we can perform fast, meaningful searches.
Why Is This Step Important?
Semantic Search: Vectors allow us to find templates based on meaning, not just exact matches.
Rich Results: With metadata stored alongside vectors, search results can display helpful context like the template name and designer.
Scalability: The database can handle thousands of templates and search queries efficiently.
With your data in Qdrant, you’re now ready to build the search interface that ties everything together.
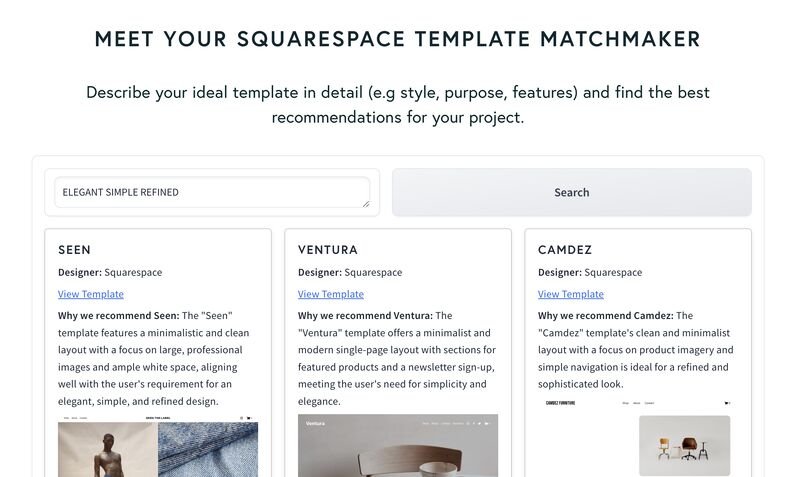
Part 4: Building the Search Interface
The final piece of the puzzle is creating an interface where users can search for templates using plain language. Imagine typing something like, “I need a modern, clean design for a coffee shop” and instantly getting relevant templates with previews, links, and descriptions. That’s exactly what we’re building here.
For this, we’ll use Gradio, a library that makes creating web apps ridiculously simple.
Core Search Logic
The backbone of our search interface is a function that:
Takes the user’s query: Converts it into a vector using OpenAI’s embedding model.
Searches the Qdrant database: Finds the most relevant templates by comparing the query vector with the stored template vectors.
Formats the results: Displays the templates in a visually appealing way, with their names, designers, links, images, and explanations.
Here’s the search function:
def search_templates(query, num_results=3):
# Convert the query to an embedding
query_embedding = get_embedding(query)
# Log the search query in Firebase
db.collection('dream_themes').add({
'query': query,
'timestamp': firebase_admin.firestore.SERVER_TIMESTAMP
})
# Search Qdrant for the most relevant templates
search_results = qdrant_client.search(
collection_name='template_catalog',
query_vector=query_embedding,
limit=10 # Fetch multiple results to refine the output
)
# Prepare the results for GPT to analyze and refine
messages = [
{
"role": "user",
"content": (
f"User query: {query}\n\n" + "\n\n".join([
f"Template {idx}:\n" + "\n".join(
[f"{key}: {value}" for key, value in result.payload.items()]
)
for idx, result in enumerate(search_results, start=1)
]) +
"\n\nBased on the user query and the provided template metadata, "
"please select the most relevant templates and explain why each one matches the user's request. "
"For each selected template, include the name, designer, image URL, link, and a short explanation."
)
}
]
# Call GPT to refine the results
response = client.chat.completions.create(
model="gpt-4o", # Or "gpt-4" if you have access
messages=messages,
max_tokens=4000,
n=1,
stop=None,
temperature=1
)
gpt_output = response.choices[0].message.content.strip()
# Parse GPT’s output into structured results
selected_templates = []
template_info = {}
for line in gpt_output.split("\n"):
if line.startswith("Template"):
if template_info:
selected_templates.append(template_info)
template_info = {}
elif line.startswith("Name:"):
template_info['name'] = line.split(":", 1)[1].strip()
elif line.startswith("Designer:"):
template_info['designer'] = line.split(":", 1)[1].strip()
elif line.startswith("Image URL:"):
template_info['image_url'] = line.split(":", 1)[1].strip()
elif line.startswith("Link:"):
template_info['link'] = line.split(":", 1)[1].strip()
elif line.startswith("Explanation:"):
template_info['explanation'] = line.split(":", 1)[1].strip()
if template_info:
selected_templates.append(template_info)
# Format results as HTML
result_str = "<div class='result-grid'>"
for template in selected_templates:
result_str += "<div class='result-item'>"
result_str += f"<h3>{template['name']}</h3>"
result_str += f"<p><strong>Designer:</strong> {template['designer']}</p>"
result_str += f"<p><a href='{template['link']}' target='_blank'>View Template</a></p>"
result_str += f"<p><strong>Why we recommend {template['name']}:</strong> {template['explanation']}</p>"
result_str += f"<img src='{template['image_url']}' alt='Template Preview' style='max-width: 100%; height: auto;'>"
result_str += "</div>"
result_str += "</div>"
return result_str or "No matching templates found."
What’s Happening?
Query Embedding: The user’s search query is turned into a vector that captures its meaning.
Search Results: Qdrant compares this vector with the stored template vectors and returns the closest matches.
Refinement by GPT: GPT refines and explains the results, providing a polished, user-friendly response.
HTML Formatting: The results are displayed in a neat, visually pleasing layout.
Building the Interface
Now, let’s build the user interface using Gradio. The goal is to keep it simple:
A search box where users type their queries.
A button to trigger the search.
A results area to display the templates.
Here’s the code:
with gr.Blocks(title="Squarespace Template Finder", css="""
.gradio-container {
max-width: 1200px;
margin: 0 auto;
}
.result-grid {
display: flex;
flex-wrap: wrap;
gap: 1rem;
}
.result-item {
flex: 1 1 30%;
min-width: 250px;
border: 1px solid #ccc;
padding: 1rem;
border-radius: 5px;
box-shadow: 0 2px 5px rgba(0, 0, 0, 0.1);
}
.result-item h3 {
margin-bottom: 0.5rem;
}
.result-item img {
max-width: 100%;
height: auto;
margin-bottom: 1rem;
}
""") as demo:
with gr.Row():
search_input = gr.Textbox(placeholder="What kind of template are you looking for?", show_label=False)
search_button = gr.Button("Search")
search_output = gr.HTML()
search_button.click(
fn=search_templates,
inputs=search_input,
outputs=search_output
)
demo.launch()
Key Features
Search Box: Lets users type queries in plain language (e.g., "modern portfolio for designers").
Grid Layout: Displays results in a responsive grid with template previews, links, and explanations.
Custom Styling: A clean, professional look with CSS for better user experience.
Conclusion: Bringing It All Together
You’ve now built a complete AI-powered template search engine! Here’s what we accomplished:
Data Collection: Gathered template details with web scraping.
AI Descriptions: Enhanced metadata with GPT-4 Vision.
Vector Database: Stored everything in Qdrant for semantic search.
Search Interface: Created a user-friendly tool with Gradio.
This setup is flexible, scalable, and ready to help users find the perfect template effortlessly.
Want to take it further?